 Admin
Admin
1 min read
What is Geospatial Data: Your Essential Guide
Geospatial data, an indispensable element of modern mapping and location-based services, offers a unique perspective on our world. This article is...

Geodata projects typically require large amounts of data. They keep growing as projects evolve. To handle such growing amounts of data, cloud solutions become more and more popular replacing classical desktop applications. However, such geodata projects commonly involve a highly heterogeneous set of data files and formats that are not optimised for cloud applications. The large variety of files and formats originates from the different sensor types and survey purposes. For instance, large offshore infrastructure projects typically involve data from satellites, but also from hydroacoustic measurements and seafloor samples. Efficient data management therefore requires the unification of the data files into formats optimised for cloud solutions. Such a big-data-ready format is the Parquet file and the GeoParquet file for geodata, which we will introduce in this blog.
Ever larger projects and increasing data volumes require efficient ways to store, transfer, and analyse data. The Apache Software Foundation tackled this problem by introducing the Apache Parquet file format. The foundation has a large community with over 8,400 committers, provides open-source software, and is sponsored by all Big Tech companies (AWS, Google, Apple, Microsoft, Facebook) and many other big companies (e.g., VISA, IBM, Salesforce, Indeed, Huawei). With this immense technological and financial support, the Parquet format, software, and infrastructure will continue to be maintained and improved in the foreseeable future.
The first version of the Parquet format, 1.0.0, was released in July 2013 (Wikipedia). The current file format version is 2.9.0, marking it a well-established file format in the software industry. Prominent Parquet format users dealing with large data sets include, e.g., Uber, Airbnb, and Facebook. In addition, the developer community introduced the GeoParquet file format a few years ago (the official repository was created on 08/2021). The GeoParquet format optimises the Parquet format for geospatial data, e.g., storing specific geodata types (point, line, polygon) and their location information (CRS - coordinate reference system) for correct map display. Despite its quite recent development, the GeoParquet has been integrated into major commercial GIS software such as ESRI’s ArcGIS (ArcGIS Geoanalytics Engine) and the open-source GIS software, QGIS.
💡 Parquet/GeoParquet is an open-source data format developed and maintained by the Apache Software Foundation.
👉 Our cloud-native geodata SaaS, TrueOcean and TrueEarth, operate with the Apache Parquet, making use of its benefits for complex and large datasets. While several data storage formats exist, Parquet's unique combination of the listed advantages below, wide compatibility, and its continuous enhancements make it a top contender for becoming the de facto standard in cloud data storage. In short, TrueOcean/TrueEarth is well-positioned in a world drifting towards enormous data volumes, and calling for unified, efficient standards.
“Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk (…)” (Apache Parquet).
Parquet is declared a column-oriented file format. This orientation makes exploring data more efficient compared to row-based file formats like CSV as non-relevant data can be skipped quickly (Databricks). Although declared column-oriented, the Parquet file format actually has a hybrid structure (see Figure 1). In a Parquet file, data are split into row groups, which are then column-oriented.
The hybrid Parquet structure performs very well for efficient filtering, query searching, and extracting specific data ranges (rows) of selected columns. Pure row- or pure column-based formats would often require a full scan of the data for the same query.
Using the data example of Figure 1, a typical query would be to extract the average elevation across all entries in a specific geographic region. In a row-based format structure, the system would need to scan each row sequentially to fetch the “LONG”, “LAT”, and “ELEVATION” data and then filter for the specific geographic region. This multitude of scans becomes a hurdle in larger datasets. A strict column-based structure scans only the “LONG”, “LAT”, and “ELEVATION” columns consecutively and applies the filter to the geographic region. Although this approach scans less data, it still requires entire columns to be read.
The hybrid-based structure of Parquet files only allows reading the row groups within the specific geographic region and then the desired columns are scanned within these row groups. This means, that only a fraction of the dataset has to be scanned to extract the queried information, making hybrid structures often an efficient choice for big data and large projects.
The hybrid structure also favours efficient data compression types which are important to reduce file sizes and latencies (read/write operation times). Parquet supports different compression algorithms, including snappy, gzip, lzo, brotli, lz4, zstd, lz4_raw. Each of these is optimised for different purposes. For example, the snappy algorithm excels the speed for read/write operations. In contrast, the gzip algorithm provides high compression rates but slows down write/read operations. The zstd compression balances between snappy and gzip. Also, for plain encoding of data types stored in the file, all types are supported by Parquet.
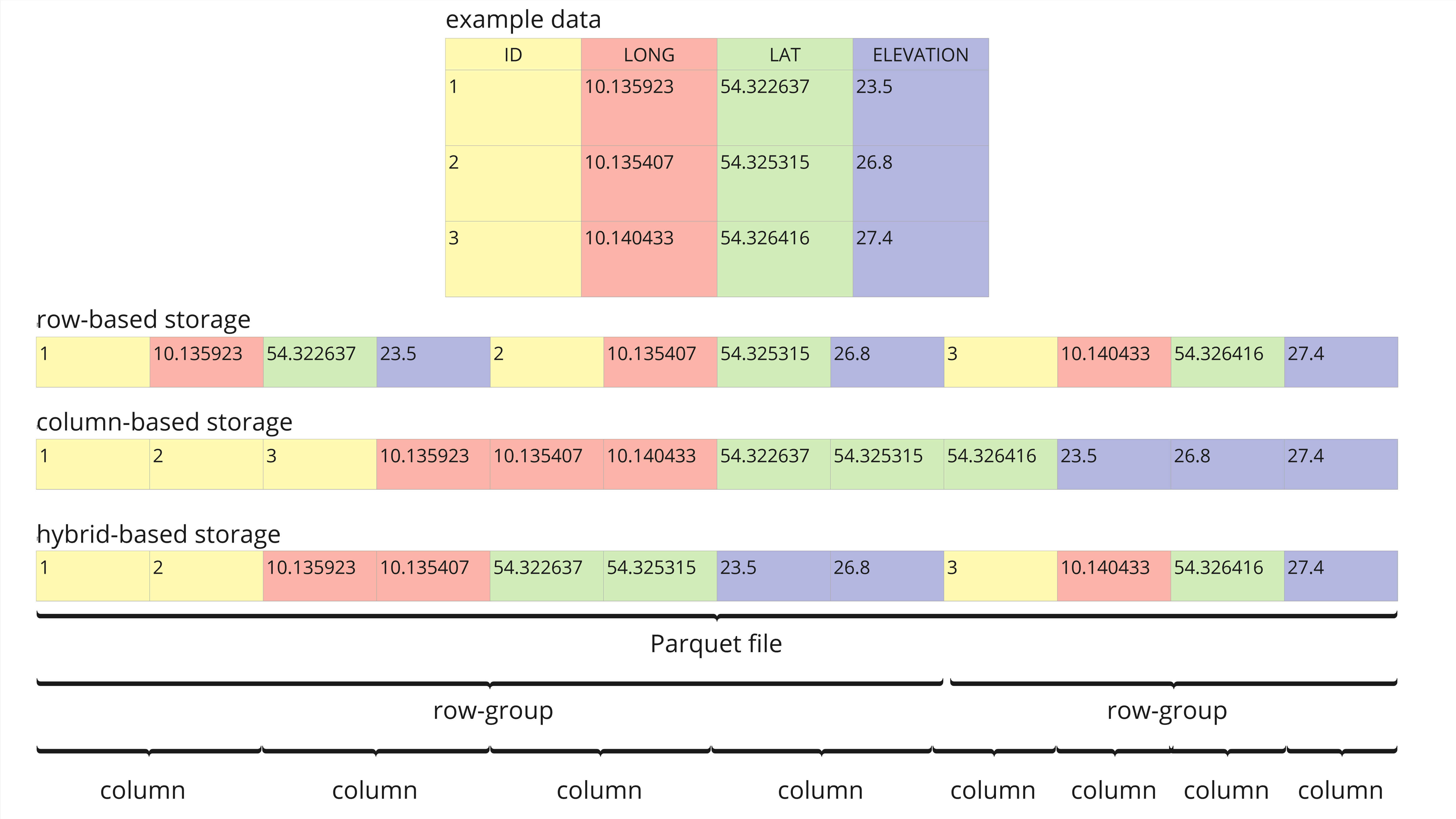
Figure 1: Example data set that compares row-based, column-based, and hybrid-based storage structures (adapted from towardsdatascience). The data set contains typical columns for geospatial data, like “ID”, “LONG”, “LAT”, and “ELEVATION”.
💡 The Parquet/GeoParquet format is built for efficient data storage and retrieval, especially on cloud storage and big data.
The Parquet and GeoParquet formats come with several advantages which we describe below:
✅ Open-source data format
✅ Transparent development and maintenance (See Parquet Format)
✅ Large financial and technical support via the Apache Software Foundation
✅ Robust security features to protect sensitive data in file storage and transfer
✅ Compatible with all programming languages for simple implementation (read/inspect/write) into existing code and infrastructures
✅ Optimised for big data of any kind (e.g., structured data tables, images, videos, documents)
✅ Allows for complex nested structures
✅ Supports high-performance queries to efficiently retrieve specific parts of the data by using techniques like data skipping and filtering
✅ Optimised for cloud environments
Despite these manifold advantages, the Parquet and GeoParquet formats also come with some disadvantages when compared to conventional, common formats used in marine survey projects.
Typical marine survey projects are often challenged by very heterogeneous data formats and sensor-specific data structures. Data management with the Parquet format would require unifying the data formats and converting the sensor-specific files into Parquet. However, once such a conversion algorithm has been written, it can be applied to all project data of that type and opens up all advantages of the Parquet framework for project data management.
We converted common marine sensor data into Parquet files and achieved compression rates of up to 44x times compared to the original file size (Table 1).
|
Sensor type |
Sensor format |
Original file size [MB] |
Parquet file size [MB] |
Compression factor |
|
Multibeam |
ALL (Kongsberg) |
80 |
25 |
3.2 |
|
Multibeam |
S7K (Reson) |
101 |
29 |
3.5 |
|
Side scan sonar |
XTF (Triton) |
96 |
84 |
1.1 |
|
Side scan sonar |
JSF (EdgeTech) |
84 |
71 |
1.2 |
|
Sub-bottom profiler |
SEGY (SEG) |
80 |
62 |
1.3 |
|
Miscellaneous |
CSV |
89 |
2 |
44.5 |
Table 1: Compression rates between common marine sensor data file formats and the Parquet format.
Also, writing Parquet files could take more time than simple row-based formats (e.g., CSV) and consumes more CPU as it requires additional parsing (Blog). Therefore, row-based formats may be the preferred option when storing small data files (Blog). However, data volumes are constantly increasing and management of big data has become the new usual. This calls for big-data routines and file formats supporting big-data management, such as the Parquet framework.
💡 Parquet/GeoParquet compression rates compared to common marine survey data file formats can be between 1.1x and 44.5x and hence can save storage space for large project data sets. At the same time, the data can be efficiently retrieved from the file by advanced filter options.
Authors
Daniel Wehner, R&D Geophysicist at north.io ✉️
Sergius Dell, Software Developer at north.io
1 min read
Geospatial data, an indispensable element of modern mapping and location-based services, offers a unique perspective on our world. This article is...

Introduction: The Challenge of Diverse Geospatial Data in Offshore Wind Projects Offshore wind projects are a testament to the synergy between...

The rapid growth of offshore wind farms has led to an increased demand for accurate and reliable data and data management. The marine data could be...
Building on the progress we’ve made over the past year with the development and release of TrueOcean’s Geodata Processing Engine, we’re excited to...