 Admin
Admin
1 Min. Lesezeit
Was sind Geodaten: Ihr elementarer Leitfaden
Geodaten, ein unverzichtbares Element moderner Kartierungs- und standortbezogener Dienste, bieten eine einzigartige Perspektive auf unsere Welt....

Geodatenprojekte erfordern in der Regel große Datenmengen. Diese wachsen mit der Entwicklung der Projekte ständig an. Um diese wachsenden Datenmengen zu bewältigen, werden Cloud-Lösungen immer beliebter und ersetzen die klassischen Desktop-Anwendungen. Solche Geodatenprojekte umfassen jedoch in der Regel sehr heterogene Dateien und Datenformate, die nicht für Cloud-Anwendungen optimiert sind. Die große Vielfalt an Dateien und Formaten ergibt sich aus den unterschiedlichen Sensortypen und Erhebungszwecken. So werden bei großen Offshore-Infrastruktur-projekten in der Regel Daten von Satelliten, aber auch von hydroakustischen Messungen und Meeresbodenproben verwendet. Eine effiziente Datenverwaltung erfordert daher die Vereinheitlichung der Datenformate, die für Cloud-Lösungen optimiert sind. Ein solches Big-Data-fähiges Format ist die Parquet-Datei und die GeoParquet-Datei für Geodaten, die wir in diesem Blog vorstellen.
Immer größere Projekte und steigende Datenmengen erfordern effiziente Methoden zur Speicherung, Übertragung und Analyse von Daten. Die Apache Software Foundation hat sich dieses Problems angenommen und das Apache Parquet-Dateiformat eingeführt. Die Stiftung verfügt über eine große Community mit mehr als 8.400 Mitwirkenden, stellt Open-Source-Software bereit und wird von allen Big-Tech-Unternehmen (AWS, Google, Apple, Microsoft, Facebook) sowie anderen großen Unternehmen (z. B. VISA, IBM, Salesforce, Indeed, Huawei) unterstützt. Mit diesem technologischen und finanziellen Hintergrund werden das Parquet-Format, die Software und die Infrastruktur in absehbarer Zukunft weiter gepflegt und verbessert.
Die erste Version des Parquet-Formats, 1.0.0, wurde im Juli 2013 veröffentlicht (Wikipedia). Die aktuelle Version des Dateiformats ist 2.9.0, was es zu einem etablierten Dateiformat in der Softwarebranche macht. Zu den prominenten Nutzern des Parquet-Formats, die mit großen Datensätzen arbeiten, gehören z. B. Uber, Airbnb und Facebook. Darüber hinaus hat die Entwicklergemeinschaft das GeoParquet-Dateiformat vor einigen Jahren eingeführt (das offizielle Repository wurde am 20.08.2021 eingerichtet). Das GeoParquet-Format optimiert das Parquet-Format für Geodaten, z. B. durch die Speicherung bestimmter Geodatentypen (Punkt, Linie, Polygon) und ihrer Standortinformationen (CRS - coordinate reference system) für die korrekte Kartendarstellung. Obwohl das GeoParquet erst vor kurzem entwickelt wurde, ist es bereits in große kommerzielle GIS-Software wie ArcGIS (ArcGIS Geoanalytics Engine) von ESRI und in die Open-Source-GIS-Software QGIS integriert worden.
💡 Parquet/GeoParquet ist ein Open-Source-Datenformat, das von der Apache Software Foundation entwickelt und gepflegt wird.
👉 Unsere Cloud-nativen Geodaten-SaaS, TrueOcean und TrueEarth, arbeiten mit Apache Parquet und nutzen dessen Vorteile für komplexe und große Datensätze. Es gibt zwar mehrere Datenspeicherformate, aber die einzigartige Kombination der unten aufgeführten Vorteile, die breite Kompatibilität und die kontinuierlichen Verbesserungen machen Parquet zu einem Top-Anwärter darauf, der De-facto-Standard für die Cloud-Datenspeicherung zu werden. Kurz gesagt, TrueOcean/TrueEarth ist in einer Welt, die auf enorme Datenmengen zusteuert und nach einheitlichen, effizienten Standards verlangt, gut positioniert.
“Apache Parquet ist ein quelloffenes, spaltenorientiertes Dateiformat, das für die effiziente Speicherung und Abfrage von Daten entwickelt wurde. Es bietet effiziente Datenkompressions- und Kodierungsverfahren mit verbesserter Leistung, um komplexe Daten in großen Mengen zu verarbeiten (...)” (Apache Parquet).
Parquet ist ein spaltenorientiertes Dateiformat. Diese Ausrichtung macht die Untersuchung von Daten effizienter als zeilenbasierte Dateiformate wie CSV, da nicht relevante Daten schnell übersprungen werden können (Databricks). Obwohl es als spaltenorientiert deklariert ist, hat das Parquet-Dateiformat in Wirklichkeit eine hybride Struktur (siehe Abbildung 1). In einer Parquet-Datei werden die Daten in Zeilengruppen aufgeteilt, die dann spaltenorientiert sind.
Die hybride Parquet-Struktur eignet sich sehr gut zum effizienten Filtern, zur Abfragesuche und zum Extrahieren bestimmter Datenbereiche (Zeilen) von ausgewählten Spalten. Reine zeilen- oder spaltenbasierte Formate würden für dieselbe Abfrage oft einen vollständigen Scan der Daten erfordern.
Am Beispiel der Daten in Abbildung 1 würde eine typische Abfrage darin bestehen, die durchschnittliche Höhe über alle Einträge in einer bestimmten geografischen Region zu extrahieren. In einer zeilenbasierten Formatstruktur müsste das System jede Zeile nacheinander abfragen, um die Daten "LONG", "LAT" und "ELEVATION" zu erhalten und dann nach der spezifischen geografischen Region zu filtern. Diese Vielzahl von Abfragen wird bei größeren Datensätzen zu einer Hürde. Bei einer strikt spaltenbasierten Struktur werden nur die Spalten "LONG", "LAT" und "ELEVATION" nacheinander durchsucht und der Filter auf die geografische Region angewendet. Obwohl bei diesem Ansatz weniger Daten gescannt werden, müssen immer noch ganze Spalten gelesen werden.
Die hybride Struktur von Parquet-Dateien erlaubt nur das Lesen der Zeilengruppen innerhalb der spezifischen geografischen Region, und dann werden die gewünschten Spalten innerhalb dieser Zeilengruppen gescannt. Dies bedeutet, dass nur ein Bruchteil des Datensatzes gescannt werden muss, um die abgefragten Informationen zu extrahieren, was hybride Strukturen oft zu einer effizienten Wahl für Big Data und große Projekte macht.
Die hybride Struktur begünstigt auch effiziente Datenkompressionsarten, die wichtig sind, um Dateigrößen und Latenzen (Lese-/Schreibzeiten) zu reduzieren. Parquet unterstützt verschiedene Kompressionsalgorithmen, darunter snappy, gzip, lzo, brotli, lz4, zstd, lz4_raw. Jeder dieser Algorithmen ist für unterschiedliche Zwecke optimiert. Der snappy-Algorithmus beispielsweise zeichnet sich durch seine hohe Geschwindigkeit bei Lese- und Schreibvorgängen aus. Im Gegensatz dazu bietet der gzip-Algorithmus hohe Kompressionsraten, verlangsamt aber Schreib-/Lesevorgänge. Die zstd-Komprimierung bietet ein Gleichgewicht zwischen snappy und gzip. Auch bei der einfachen Kodierung der in der Datei gespeicherten Datentypen werden alle Typen von Parquet unterstützt.
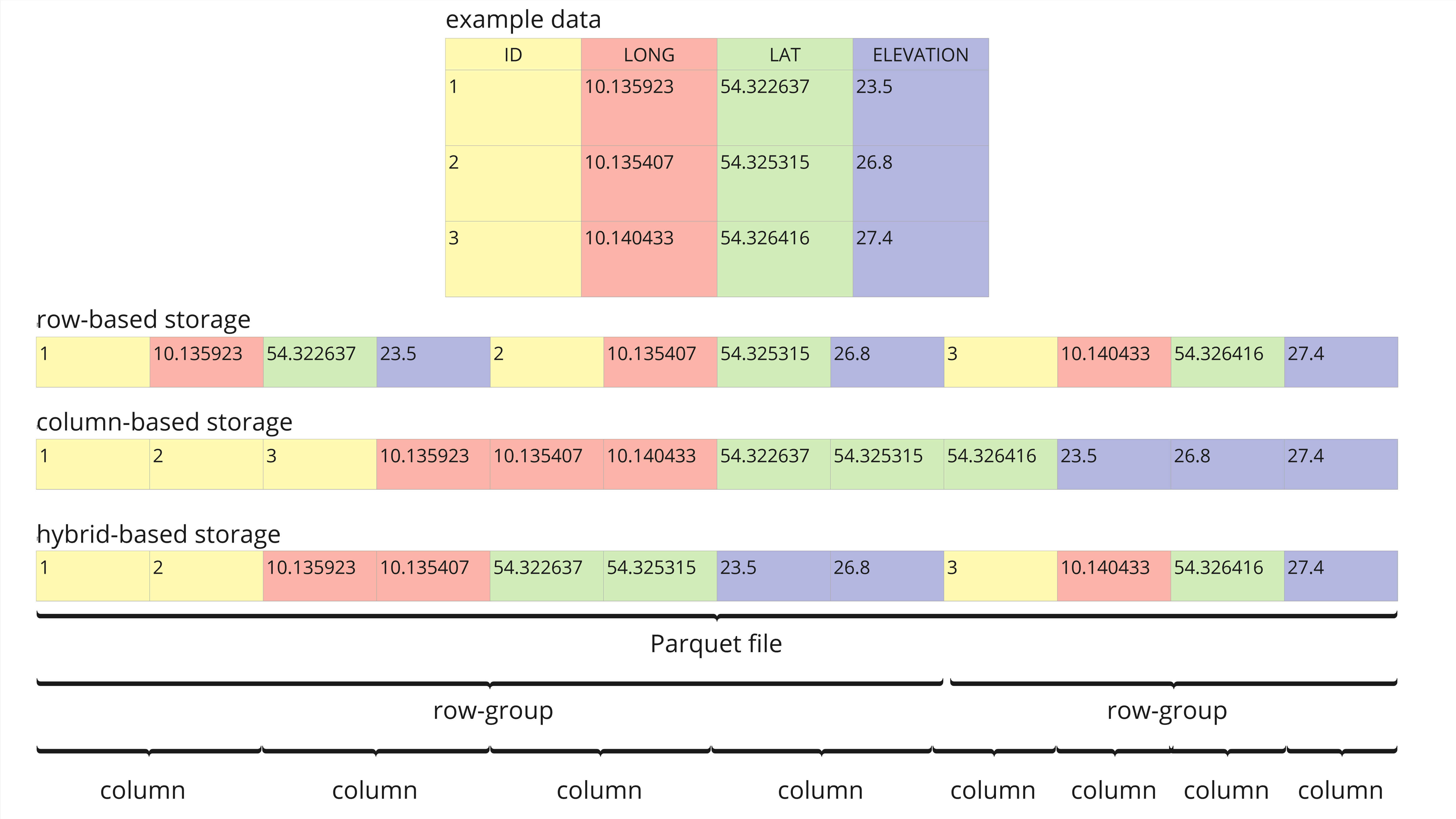
Abbildung 1: Beispieldatensatz, der zeilenbasierte, spaltenbasierte und hybridbasierte Speicherstrukturen vergleicht (angepasst von towardsdatascience). Der Datensatz enthält typische Spalten für Geodaten, wie "ID", "LONG", "LAT" und "ELEVATION".
💡 Das Parquet/GeoParquet-Format wurde für eine effiziente Datenspeicherung und -abfrage entwickelt, insbesondere für Cloud-Speicher und Big Data.
Die Formate Parquet und GeoParquet haben mehrere Vorteile, die wir wie folgt beschreiben:
✅ Open-Source-Datenformat
✅ Transparente Entwicklung und Wartung (siehe Parquet Format)
✅ Umfangreiche finanzielle und technische Unterstützung durch die Apache Software Foundation
✅ Robuste Sicherheitsfunktionen zum Schutz sensibler Daten bei der Speicherung und Übertragung von Dateien
✅ Kompatibel mit allen Programmiersprachen zur einfachen Implementierung (Lesen/Inspektieren/Schreiben) in bestehenden Code und Infrastrukturen
✅ Optimiert für Big Data jeglicher Art (z. B. strukturierte Datentabellen, Bilder, Videos, Dokumente)
✅ Ermöglicht komplexe verschachtelte Strukturen
✅ Unterstützt hochleistungsfähige Abfragen zum effizienten Abrufen bestimmter Teile der Daten durch Techniken wie Datenüberspringung und Filterung
✅ Optimiert für Cloud-Umgebungen
Trotz dieser vielfältigen Vorteile haben die Formate Parquet und GeoParquet auch einige Nachteile im Vergleich zu den konventionellen, gängigen Formaten, die in Meeresvermessungsprojekten verwendet werden.
Typische Meeresvermessungsprojekte haben oft mit sehr heterogenen Datenformaten und sensorspezifischen Datenstrukturen zu kämpfen. Die Datenverwaltung mit dem Parquet-Format würde eine Vereinheitlichung der Datenformate und eine Konvertierung der sensorspezifischen Dateien in Parquet erfordern. Ist ein solcher Konvertierungsalgorithmus jedoch einmal geschrieben, kann er auf alle Projektdaten dieses Typs angewandt werden und erschließt alle Vorteile des Parquet-Frameworks für das Projektdatenmanagement.
Wir konvertierten gängige Meeressensordaten in Parquet-Dateien und erreichten Kompressionsraten von bis zu 44-facher Größe im Vergleich zur ursprünglichen Dateigröße (Tabelle 1).
|
Sensor type |
Sensor format |
Original file size [MB] |
Parquet file size [MB] |
Compression factor |
|
Multibeam |
ALL (Kongsberg) |
80 |
25 |
3.2 |
|
Multibeam |
S7K (Reson) |
101 |
29 |
3.5 |
|
Side scan sonar |
XTF (Triton) |
96 |
84 |
1.1 |
|
Side scan sonar |
JSF (EdgeTech) |
84 |
71 |
1.2 |
|
Sub-bottom profiler |
SEGY (SEG) |
80 |
62 |
1.3 |
|
Miscellaneous |
CSV |
89 |
2 |
44.5 |
Tabelle 1: Komprimierungsraten zwischen gängigen Dateiformaten für Meeressensordaten und dem Parquet-Format.
Außerdem kann das Schreiben von Parquet-Dateien mehr Zeit in Anspruch nehmen als einfache zeilenbasierte Formate (z. B. CSV) und verbraucht mehr CPU, da es zusätzliches Parsing erfordert (Blog). Daher können zeilenbasierte Formate die bevorzugte Option für die Speicherung kleiner Datendateien sein (Blog). Die Datenmengen nehmen jedoch ständig zu, und die Verwaltung von Big Data ist zum neuen Standard geworden. Dies erfordert Big-Data-Routinen und Dateiformate, die das Big-Data-Management unterstützen, wie z. B. das Parquet-Framework.
💡 Die Komprimierungsraten von Parquet/GeoParquet liegen im Vergleich zu den üblichen Dateiformaten für Meeresvermessungsdaten zwischen dem 1,1-fachen und dem 44,5-fachen und können daher bei großen Projektdatensätzen Speicherplatz sparen. Gleichzeitig können die Daten durch erweiterte Filteroptionen effizient aus der Datei abgerufen werden.
Autoren
Daniel Wehner, R&D Geophysicist bei north.io ✉️
Sergius Dell, Software Developer bei north.io
1 Min. Lesezeit
Geodaten, ein unverzichtbares Element moderner Kartierungs- und standortbezogener Dienste, bieten eine einzigartige Perspektive auf unsere Welt....

Einleitung: Die Herausforderung unterschiedlicher Geodaten bei Offshore-Windprojekten Offshore-Windprojekte sind ein Beweis für die Synergie zwischen...
Hintergrund Im Bereich der Geodaten spielen Metadaten eine zentrale Rolle bei der Gewährleistung der Integrität, Nutzbarkeit und Zugänglichkeit von...

Das rasche Wachstum von Offshore-Windparks hat zu einem erhöhten Bedarf an genauen und zuverlässigen Daten und Datenmanagement geführt. Die...